本教程将实际操作使用Python Scrapy框架爬取传智播客教师页面教师的个人信息。 爬取页面网址:http://www.itcast.cn/channel/teacher.shtml#ac Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于...
”python 爬虫 scrapy 框架 数据采集“ 的搜索结果
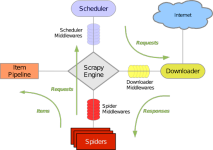
Python爬虫:Scrapy框架基础框架结构及腾讯爬取Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据。...
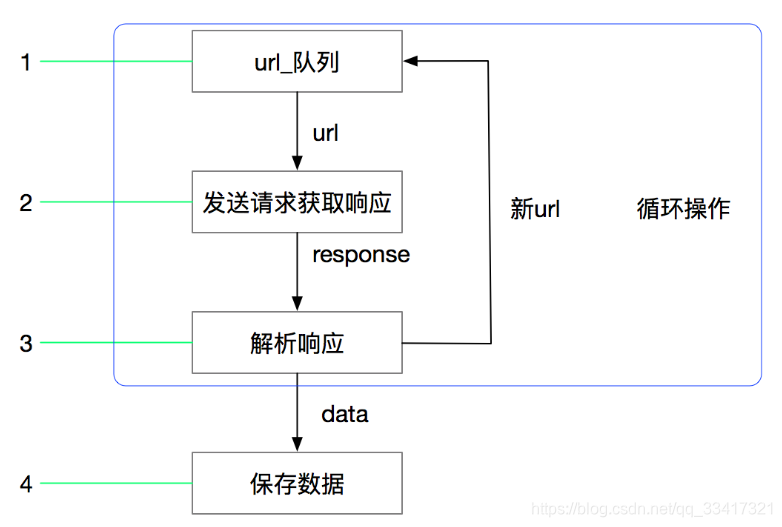
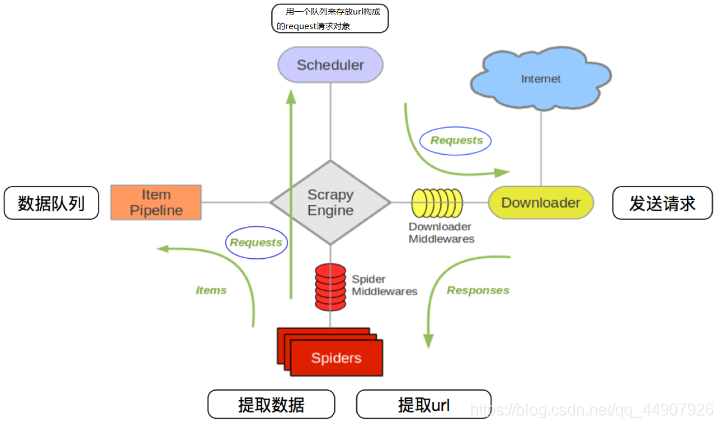
文章目录Scrapy 框架一、 简介1、 介绍2、 环境配置3、 常用命令4、 运行原理4.1 流程图4.2 部件简介4.3 运行流程二、 创建项目1、 修改配置2、 创建一个项目3、 定义数据4、 编写并提取数据5、 存储数据6、 运行...
【课程简介】 本课程适合所有需要弥补python网络爬虫的同学,课件内容制作精细,由浅入深...10-Scrapy爬虫框架(共34页).pptx 11-Scrapy爬虫基本使用(共32页).pptx 12-实例4-股票数据定向Scrapy爬虫(共23页).pptx
本系统采用Scrapy爬虫框架来开发,使用Xpath网页提取技术对下载网页进行内容解析,使用Redis做分布式,使用MongoDB对提取的数据进行存储,使用Django开发可视化界面对爬取的结果进行友好展示,设计并实现了针对链家...
本文为大家介绍利用python爬虫scrapy框架爬取药网,希望可以帮助到大家。 cmd 命令创建项目 scrapy startproject yiyaowang cd yiyaowang scrapy genspider yaowang yaowang.com 先进入settings.py文件将服从...
Python网络爬虫教程 数据采集 信息提取课程 10-Scrapy爬虫框架(共34页).pptx Python网络爬虫教程 数据采集 信息提取课程 11-Scrapy爬虫基本使用(共32页).pptx Python网络爬虫教程 数据采集 信息提取课程 12-实例...
Python爬虫开发 基于Scrapy爬虫框架实现的信息数据采集抓取批量爬取网站人物信息 含文档、源代码及采集的案例数据 Python爬虫开发进阶技术,技术爬虫框架可快速开发高效稳定的爬虫,且可基于框架进行补充,开发出...
scrapyScrapy:Python的爬虫框架实例Demo抓取:汽车之家、瓜子、链家 等数据信息版本+环境库Python2.7 + Scrapy1.12初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据...
题记:早已听闻python爬虫框架的大名。近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享。有表述不当之处,望大神们斧正。一、初窥ScrapyScrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架...

Scrapy 是用 Python 实现的一个为了采集网站数据、提取结构性数据而编写的应用框架。常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定...

使用Scrapy可以很方便的完成网上数据的采集工作,它为我们完成了大量的工作,而不需要自己费大力气去开发。 首先先要回答一个问题。 问:把网站装进爬虫里,总共分几步? 答案很简单,四步: 新建项目 (Project):...

Scrapy 是一个基于 Twisted 实现的异步处理爬虫框架,该框架使用纯 Python 语言编写。Scrapy 框架应用广泛,常用于数据采集、网络监测,以及自动化测试等。

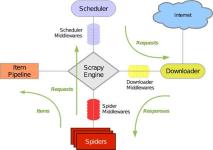
Python网络爬虫教程 数据采集 信息提取课程 10-Scrapy爬虫框架(共34页).pptx Python网络爬虫教程 数据采集 信息提取课程 11-Scrapy爬虫基本使用(共32页).pptx Python网络爬虫教程 数据采集 信息提取课程 12-实例...
Scrapy 是一个 Python 爬虫框架,它的特点是高效、可扩展和可 定制性强。它提供了很多实用工具,包括网络爬虫框架、数据提 取、数据存储等,可以方便地用于数据采集和处理。 2. Beautiful Soup Beautiful Soup 是一...
最近自己用一个python里面非常常用的爬虫框架scrapy爬取豆瓣Top250电影榜单的一些数据,具体过程如下: 首先提前下载好一些库,最主要的是scrapy和selenium 第一: 开启一个scrapy项目,创建scrapy项目需要在命令行...
Scrapy 是一套基于Twisted、纯python实现的异步爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,相当的方便~ 整体架构和组成 Scrapy Engine(引擎) 引擎负责...

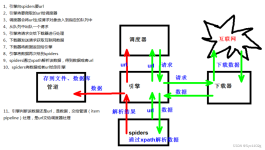
Scrapy是一个基于Python的Web爬虫框架,可以快速方便地从互联网上获取数据并进行处理。它的设计思想是基于Twisted异步...本教程将介绍如何使用Scrapy框架来编写一个简单的爬虫,从而让您了解Scrapy框架的基本使用方法。

推荐文章
- 手写一个SpringMVC框架(有助于理解springMVC) 侵立删_springmvc可以用来写安卓后端吗-程序员宅基地
- 线性判别分析LDA((公式推导+举例应用))_lda推导-程序员宅基地
- C# 结构体(Struct)精讲_c# struct-程序员宅基地
- 支付宝Wap支付你了解多少?_阿里wap支付-程序员宅基地
- Java计算器编写,实现循环输入_java简易计算器可使用户多次输入-程序员宅基地
- 【多维Dij+DP】牛客小白月赛75 D-程序员宅基地
- Android之内存优化与OOM-程序员宅基地
- Azure Machine Learning - 视频AI技术_azure ai 視頻索引器-程序员宅基地
- 个人知识管理软件使用感受-程序员宅基地
- WWDC2019 ------深入理解App启动_wwdc app启动-程序员宅基地